Arctic Speculator
Arctic Speculator provides highly efficient, lightweight draft models for speculative decoding in ArcticInference. Arctic Speculator delivers significant latency reductions by quickly generating high-quality speculative tokens for verification within vLLM’s existing speculative decoding pipeline.
Core Technique
Arctic Speculator supports two optimized, lightweight architectures as draft models for generating speculative token candidates:
MLP-based Speculator:
This simple yet effective feed-forward neural network uses the final hidden states and recent token IDs from the main LLM to propose multiple candidate tokens simultaneously. By efficiently propagating hidden state information across decoding steps, the MLP-based speculator achieves a strong balance between model simplicity, low latency, and high acceptance rates.
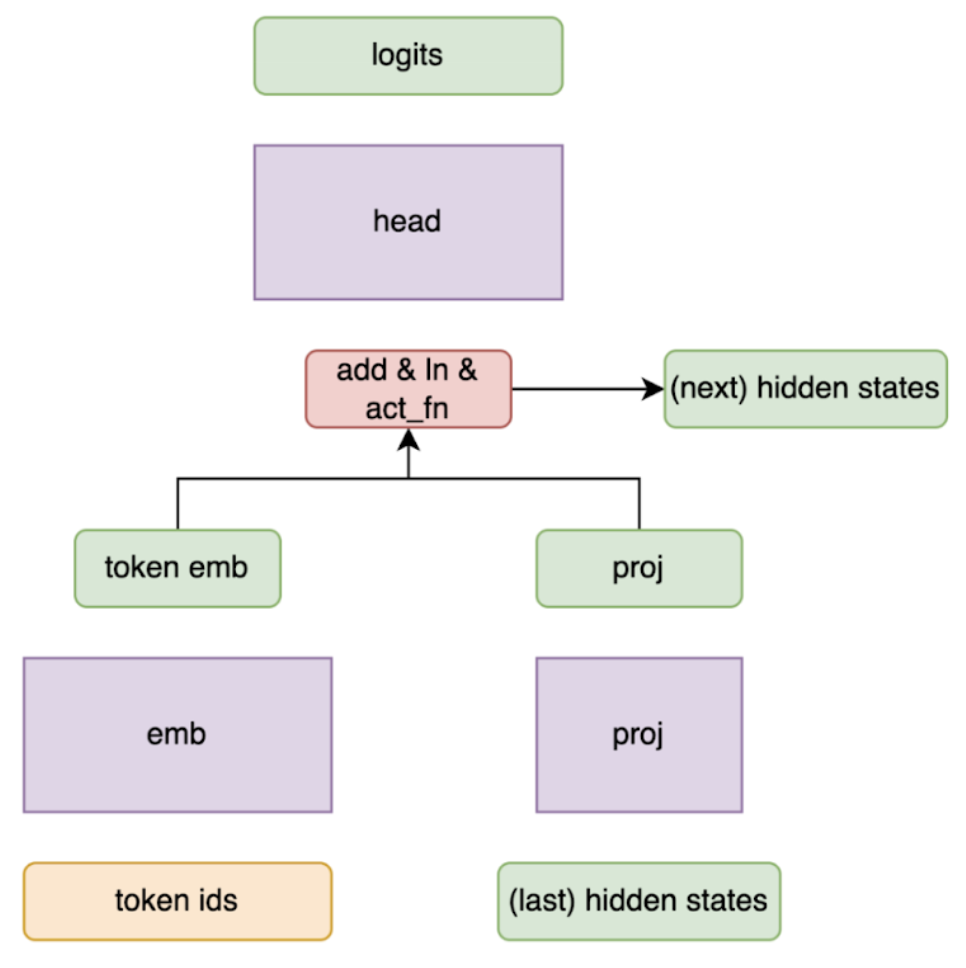
Illustration of the MLP-based Arctic Speculator.
LSTM-based Speculator:
Building on the MLP structure, the LSTM-based speculator incorporates the LSTM gating mechanisms (forget, input, output, and cell gates) to capture sequential token dependencies more effectively. This design provides superior predictive accuracy and improved acceptance rates at only a minimal additional computational cost.
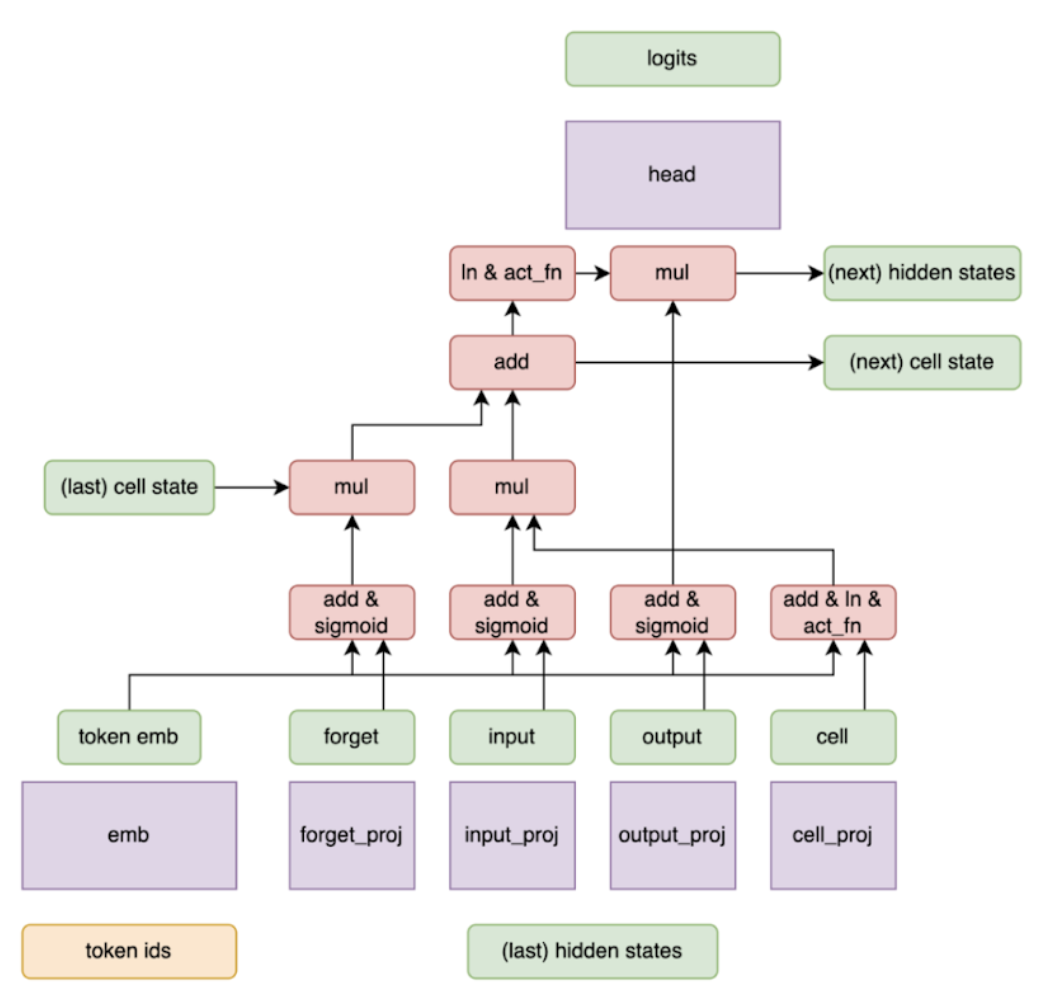
Illustration of the LSTM-based Arctic Speculator.
Several pre-trained draft models are available in the Snowflake speculators collection on Huggingface.
The draft models provided by Arctic Speculator integrate seamlessly with vLLM’s existing scorer and verifier components, which evaluate the proposed tokens and ensure correctness by verifying them using the main LLM.
To maximize throughput and reduce inference latency, Arctic Speculator employs the following key optimizations (benchmarked against vLLM v0.8.4):
FP8 Quantization: Lowers memory demand and significantly improves speculation speed.
Tensor Parallelism: Distributes the workload across multiple GPUs using tensor-parallelism.
Communication Optimization: Reduces cross-GPU communication overhead by computing local Top-K logits before aggregation.
CUDA Graphs: Captures the full speculation loop into a single CUDA graph, eliminating kernel launch overhead.
Together, these optimizations achieve over 3× improvement in draft model latency (from ~1.47 ms/token to ~0.47 ms/token) relative to vLLM v0.8.4.
Benchmark Results
Arctic Speculator achieves significant performance improvements across key benchmarks when combined with vLLM v0.8.4:
Workload |
No Spec |
N-gram |
EAGLE |
Arctic |
Arctic + Suffix |
|---|---|---|---|---|---|
ShareGPT |
76.0 tok/s |
91.2 tok/s |
102 tok/s |
172 tok/s |
179 tok/s |
HumanEval |
77.2 tok/s |
100 tok/s |
112 tok/s |
203 tok/s |
217 tok/s |
SWE-Bench |
75.8 tok/s |
175 tok/s |
Error |
294 tok/s |
302 tok/s |
Mixed |
82.9 tok/s |
112 tok/s |
Error |
184 tok/s |
209 tok/s |
Combining with Suffix Decoding
Arctic Speculator can also integrate with Suffix Decoding for additional performance benefits on workloads exhibiting repetition, such as agentic tasks, self-refinement loops, and multi-agent pipelines. The combined mode dynamically selects the speculative strategy (suffix-based or model-based) per inference step, achieving optimal performance across diverse scenarios.
Training Custom Draft Models with ArcticTraining
If a pre-trained draft model (speculator) is not available for your target model in our public list, you can train your own using ArcticTraining. ArcticTraining supports the knowledge distillation process required to create a high-quality draft model (e.g., an MLP or LSTM speculator) that closely mimics the target model’s output distribution, which is crucial for effective speculative decoding.
To get started, refer to the MLP Speculator training examples in ArcticTraining, such as the provided Llama-3.1-8B-Instruct example, and adapt it to your specific model and training needs.
Usage Examples
Minimal configuration with Arctic Speculator (LSTM-based):
export ARCTIC_INFERENCE_ENABLED=1
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--speculative-config '{
"method": "arctic",
"model": "Snowflake/Arctic-LSTM-Speculator-Llama-3.1-8B-Instruct",
"num_speculative_tokens": 3
}'
Combined Arctic Speculator with Suffix Decoding:
export ARCTIC_INFERENCE_ENABLED=1
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--speculative-config '{
"method": "arctic",
"model": "Snowflake/Arctic-LSTM-Speculator-Llama-3.1-8B-Instruct",
"num_speculative_tokens": 3,
"enable_suffix_decoding": true
}'
Configuration Parameters
The following parameters are available under speculative-config in vLLM for
configuring Arctic Speculator:
method (str, required):
Must be set to “arctic” to enable the Arctic Speculator.
model (str, required):
Specifies the Hugging Face ID or path to the Arctic speculator model.
num_speculative_tokens (int, default: 3):
Defines the maximum number of speculative tokens generated per decoding step. Higher numbers increase throughput but may reduce the token acceptance rate. This is typically determined based on the draft model itself.
enable_suffix_decoding (bool, default: false):
Enables Suffix Decoding, recommended for tasks involving repetitive patterns.